Création d’une plateforme d’intelligence de marché pour l’assurance
Startup française spécialisée dans les données d'assurance
Une startup française devait constituer une base de données exhaustive des compagnies d’assurance et de courtage. Nous avons livré toute la stack data : agents de scraping, intégrations d’APIs tierces, base de données centralisée et API de requêtage. Le fondateur s’est concentré sur les ventes et le produit pendant que nous gérions toute la partie données.
Le défi
Le client développait un produit entièrement dépendant de données qu’il ne possédait pas encore. Il avait besoin d’une base de données complète et structurée des sociétés d’assurance et de courtage, dispersées dans des sources web non structurées. En tant que startup, il n’avait aucune équipe d’ingénierie data et un budget serré.
La valeur du produit repose sur l’exhaustivité et la précision, mais les données n’existent pas en un seul endroit. Elles sont réparties entre registres réglementaires, annuaires professionnels, sites web d’entreprises et APIs tierces, chacun avec des formats et fréquences de mise à jour différents. Le client avait un développeur web pour le front-end mais aucune capacité à construire le pipeline de données.
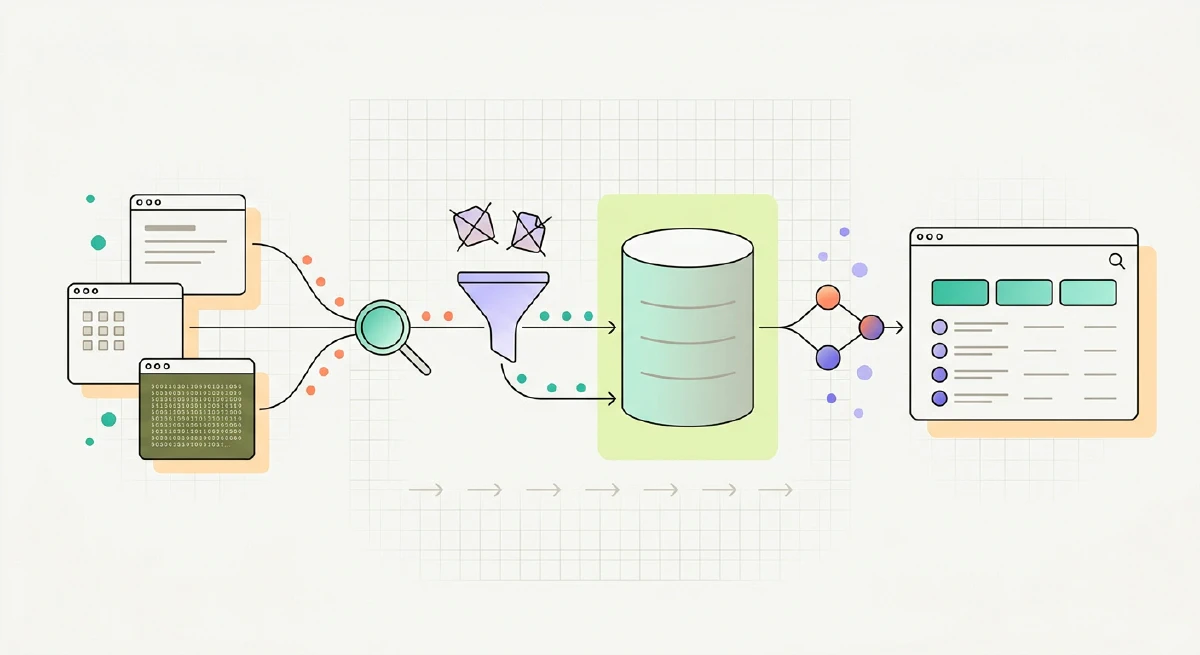
Notre approche
Nous avons construit et opéré le pipeline de données complet. La phase un (4 semaines) s’est concentrée sur les agents de scraping pour les sources à plus forte valeur, en gérant les protections anti-bot et les données non structurées. La phase deux (12 semaines) a ajouté la base de données centrale, les connecteurs d’API, des agents de scraping supplémentaires, et l’API de requêtage qui alimente le front-end du client.
Ce que nous avons construit
Agents de web scraping
Agents personnalisés collectant des données depuis des sites réglementaires, annuaires professionnels et sites d’entreprises. Conçus pour contourner les protections anti-scraping et gérer des mises en page non structurées.
Intégrations d'API tierces
Connecteurs vers des fournisseurs de données externes, enrichissant les données collectées avec des attributs d’entreprise supplémentaires et des signaux de marché.
Base de données centrale
Une base de données structurée et dédupliquée des acteurs du marché de l’assurance, optimisée pour des requêtes rapides et des mises à jour continues depuis toutes les sources de collecte.
API de requêtage
Une API en production qui expose la base de données à l’application front-end du client, supportant les recherches et filtres dont dépendent leurs utilisateurs.
Résultats
Le client a lancé son produit sur une infrastructure data complète et production-ready sans recruter d’équipe d’ingénierie data. Le fondateur s’est consacré entièrement au développement commercial et au produit front-end. La mission s’est étendue à mesure que de nouvelles sources de données émergeaient, et Stratalis continue d’opérer et d’étendre la plateforme.
Avant & Après
| Métrique | Avant | Après |
|---|---|---|
| Équipe d'ingénierie de données | Aucune | Pipeline complet, externalisé |
| Sources de données | Dispersées, manuelles | Automatisées, multi-sources |
| Délai de mise sur le marché | Bloqué par les données | 18 semaines jusqu'à la production |
| Temps du fondateur sur les données | Goulot d'étranglement principal | Zéro |